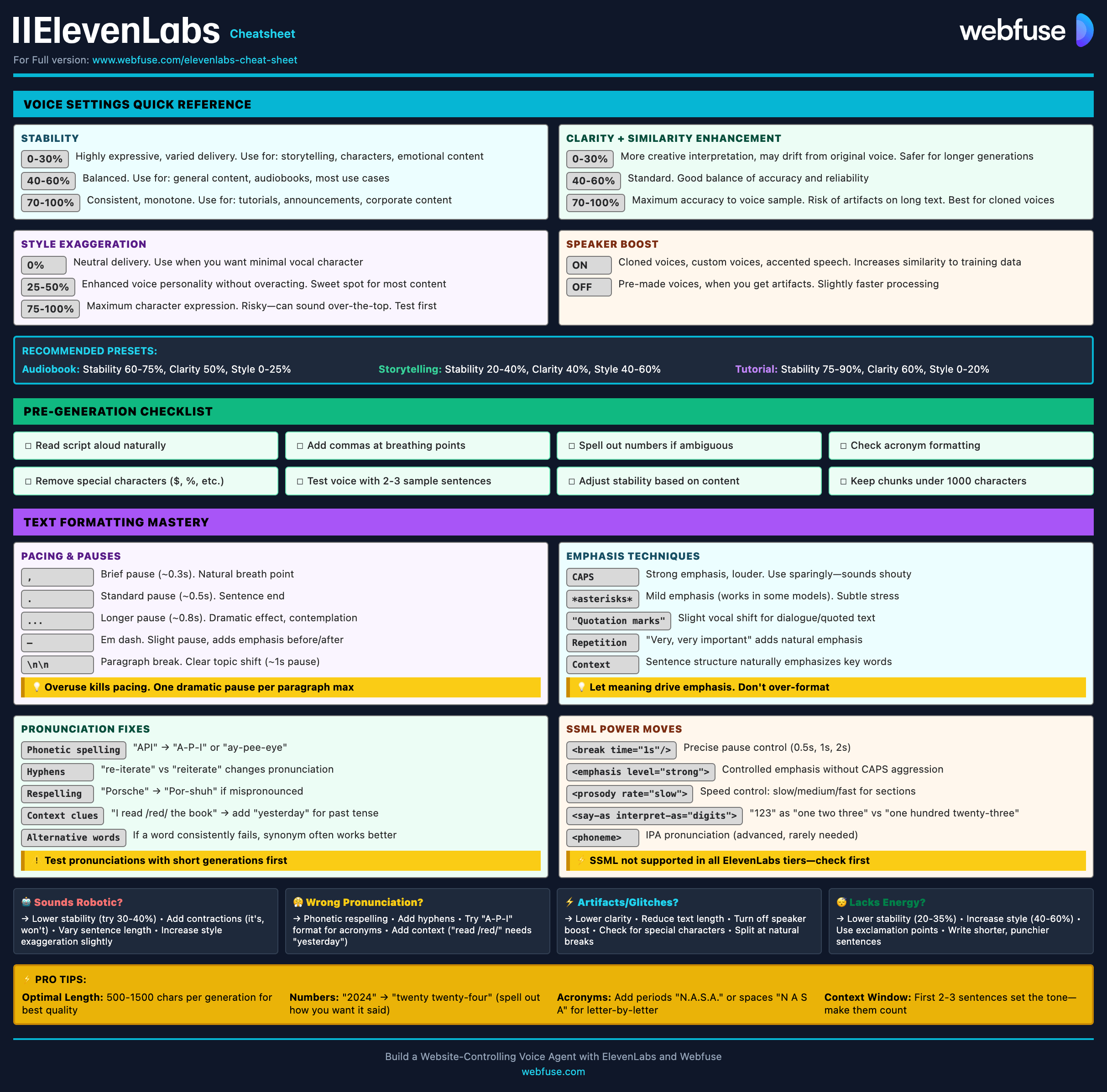
ElevenLabs Cheat Sheet
Current quick reference for the ElevenLabs platform in 2026
This cheat sheet covers the current ElevenLabs stack: text-to-speech (TTS), model selection, voice library and cloning, API usage, streaming, language support, and where agents and speech-to-text fit into the platform.
Current ElevenLabs Platform
ElevenLabs is no longer just a text-to-speech tool. The platform now spans TTS, speech-to-text, voices, agents, and other audio workflows.
Text to Speech
Core TTS models include eleven_flash_v2_5, eleven_multilingual_v2, and eleven_v3.
Speech to Text
Scribe v2 and realtime STT support transcription, timestamps, captions, and meeting-style audio workflows.
Voices
Use Voice Library, Instant Voice Cloning, Professional Voice Cloning, and Voice Design depending on speed, quality, and sharing needs.
Agents
ElevenLabs now supports agent-style, low-latency voice experiences where TTS and realtime audio matter more than one-off generation.
Music & Sound
The platform also covers music and sound effects, so ElevenLabs now sits closer to a broader audio generation stack than a TTS-only API.
Dubbing & Cleanup
Dubbing, voice isolation, and related audio cleanup workflows are now part of the product surface many users expect from ElevenLabs.
What changed since older cheat sheets?
- Older v1-era references are outdated.
- Turbo-first recommendations are no longer the best default framing.
- The product is broader now: TTS, STT, voices, agents, and audio workflows.
Quick Start Guide
Get results in 5 minutes
Complete Working Example
Copy this cURL command, replace API_KEY and run it to generate your first voice:
curl -X POST https://api.elevenlabs.io/v1/text-to-speech/21m00Tcm4TlvDq8ikWAM \ -H "xi-api-key: YOUR_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "text": "Welcome to ElevenLabs. This is your first generated voice.", "model_id": "eleven_flash_v2_5", "voice_settings": { "stability": 0.5, "similarity_boost": 0.75 } }' \ --output speech.mp3
21m00Tcm4TlvDq8ikWAM (Rachel - default female voice) Get your API key: elevenlabs.io → Developer → API Key
Choose Your Model
eleven_v3eleven_flash_v2_5eleven_multilingual_v2eleven_flash_v2_5 or eleven_multilingual_v2Tune Voice Settings
0.0 - 1.0High (0.8): Consistent & predictable
0.0 - 1.0Sweet spot: 0.75 for most cases
0.0 - 1.0Start at 0.0, increase if needed
Models Comparison
Choose the right model for your use case
| Model | Best For | Latency | Languages | Char Limit | Key Features |
|---|---|---|---|---|---|
Flash v2.5 eleven_flash_v2_5 | Real-time applications Chatbots, live agents, conversational AI | 75ms Ultra-fast | 32 languages | 40,000 ~40 min audio | • Lowest latency • Optimized for speed • WebSocket streaming • Good quality/speed balance |
Multilingual v2 eleven_multilingual_v2 | Premium quality Audiobooks, podcasts, videos | ~1-2s Slower | 29 languages Premium quality | 10,000 Longer-form narration | • Highest quality • Best for long-form content • Natural prosody • Accent preservation |
Eleven v3 eleven_v3 | Emotional & expressive Storytelling, character voices, drama | ~1-2s Slower | 70+ languages Most supported | 5,000 Designed for expressive output | • Multi-speaker dialogue • Audio tags [laughs] [whispers] • Most emotional depth • Character acting |
Scribe v2 scribe_v2 | Speech-to-text Transcription, timestamps, diarization | ~150ms realtime Realtime variant available | 90+ languages Most coverage | Audio file based | • Converts speech to text • Word-level timestamps • Speaker diarization • High accuracy |
Text Control & Formatting
Control timing, pronunciation, and speech patterns
Pauses & Timing
<break time="1.5s" />Sentence. <break time="2s" /> Next.Pronunciation Control
<phoneme alphabet="cmu-arpabet" ph="M AE1 D IH0 S AH0 N">Madison</phoneme><phoneme alphabet="ipa" ph="ˈæktʃuəli">actually</phoneme>Alias Tags
<lexeme> <grapheme>UN</grapheme> <alias>United Nations</alias> </lexeme>Speed & Pacing
0.7 - 1.2Pronunciation Dictionaries (.PLS)
- Upload custom pronunciation files
- Reusable across multiple requests
- Combine phonemes + aliases
- Case-sensitive matching
Emotion & Expression
Make AI voices sound more human and expressive without overfitting to fragile prompt tricks
Narrative Context
Add emotional context around dialogue for natural expression
"You're leaving?" she asked, her voice trembling with sadness."That's it!" he exclaimed triumphantly.v3 Audio Tags
Special tags for Eleven v3 model only
[laughs][whispers][sighs][exhales][sarcastic][curious][excited][crying][applause][clapping][gasps]Special Tags & Effects
[strong French accent] Bonjour![sings]Singing voicePunctuation Techniques
This is AMAZING!I don't know... maybe...You did what?Eleven v3 Mode Settings
Choose the right mode for your emotional needs
Voice Selection & Settings
Choose the right voice source, clone type, and settings for your use case
Current ElevenLabs Voice Stack
Voice Library
Rachel - Neutral female Adam - Deep male Bella - Soft female Voice Cloning Types
Voice Settings Presets
0.6-0.80.70.2-0.40.7-0.90.90.0-0.20.3-0.50.80.7-1.0Speaker Boost
Selection Tips
WebSocket Streaming
Real-time audio generation patterns for low-latency ElevenLabs workflows
Connection Setup
wss://api.elevenlabs.io/v1/text-to-speech/{voice_id}/stream-inputxi-api-key: YOUR_API_KEYMessage Protocol
{ "text": "Hello world", "model_id": "eleven_flash_v2_5", "voice_settings": { "stability": 0.5, "similarity_boost": 0.75 } }Chunk Management
ws.send(JSON.stringify({ text: "First chunk. " })) ws.send(JSON.stringify({ text: "Second chunk." }))Flushing & Completion
ws.send(JSON.stringify({ flush: True }))Buffering Strategy
Error Handling
- 401 - Invalid API key
- 429 - Rate limited
- 400 - Invalid chunk format
Performance Tips
- Use Flash v2.5 model
- Send 200-500 char chunks
- Flush at sentence breaks
- Keep connection alive
- Buffer 300-500ms initially
- Use complete sentences
- Avoid mid-word chunks
- Proper punctuation
- Implement reconnection
- Monitor connection health
- Handle rate limits
- Log failed chunks
API Quick Reference
Essential endpoints, model IDs, and current usage patterns
Text-to-Speech (POST)
POSThttps://api.elevenlabs.io/v1/text-to-speech/{voice_id}xi-api-key: YOUR_API_KEYContent-Type: application/json{ "text": "Your text here", "model_id": "eleven_flash_v2_5", "voice_settings": { "stability": 0.5, "similarity_boost": 0.75, "style": 0.0, "use_speaker_boost": true } }Python Example
import requests url = f"https://api.elevenlabs.io/v1/text-to-speech/{voice_id}" headers = { "xi-api-key": API_KEY, "Content-Type": "application/json" } data = { "text": "Hello world", "model_id": "eleven_flash_v2_5" } response = requests.post(url, json=data, headers=headers) with open("output.mp3", "wb") as f: f.write(response.content)
JavaScript Example
const response = await fetch(url, { method: 'POST', headers: { 'xi-api-key': API_KEY, 'Content-Type': 'application/json' }, body: JSON.stringify({ text: 'Hello world', model_id: 'eleven_flash_v2_5' }) }); const audioBuffer = await response.arrayBuffer(); const blob = new Blob([audioBuffer], { type: 'audio/mpeg' }); const urlObject = URL.createObjectURL(blob);
List Voices (GET)
GEThttps://api.elevenlabs.io/v1/voicesList Models (GET)
GEThttps://api.elevenlabs.io/v1/modelsSpeech-to-Text (POST)
POSThttps://api.elevenlabs.io/v1/speech-to-textVoice Cloning (POST)
POSThttps://api.elevenlabs.io/v1/voices/add- Upload audio files
- Provide descriptive name
- Choose cloning type (IVC/PVC)
- Optional: description, labels
Current Model IDs to Know
eleven_flash_v2_5eleven_multilingual_v2eleven_v3Language Support
Current language coverage depends on model, with Eleven v3 offering the broadest TTS support
Language Coverage by Model
Language Codes
{ "text": "Hola, ¿cómo estás?", "model_id": "eleven_multilingual_v2", "language_code": "es" }language_code when the endpoint and model support it for more predictable output. Multilingual Tips
Regional Variants
- Spanish: es-ES, es-MX, es-AR
- Portuguese: pt-PT, pt-BR
- English: en-US, en-GB, en-AU
- French: fr-FR, fr-CA
Code Switching
"Welcome to Mexico City. Bienvenidos a la Ciudad de México."Model-Specific Notes
- Best for realtime TTS
- 32 languages
- Strong default for agents
- Use for low-latency playback
- Best for polished multilingual narration
- 29 languages
- Better long-form balance
- Use when quality matters more than speed
- Broadest TTS language coverage
- 70+ languages
- Best expressive model
- Use for dialogue and emotional delivery
Special Characters
Automatic Detection
Troubleshooting
Common issues and solutions
Audio Quality Issues
- Lower stability (try 0.3-0.5)
- Increase similarity boost
- Add narrative context
- Try different voice
- Increase stability (0.7-0.8)
- Switch from v3 to Flash or Multilingual for more stable output
- Remove excessive breaks
- Simplify text formatting
- Enable speaker boost
- Reduce style exaggeration
- Fix text punctuation
- Regenerate (use 3x feature)
Voice Cloning Problems
- Use 2+ minutes of audio
- Ensure clean recording
- Single speaker only
- No background noise
- Match audio style to use case
- Adjust similarity boost
- Try PVC instead of IVC
- Test clone quality across current TTS models
- Check file format (MP3/WAV)
- Max 10 files per upload
- 1-2 min total duration
- Remove silence/pauses
Pronunciation Issues
- Use phoneme tags
- Add pronunciation dictionary
- Provide phonetic hints
- Spell out syllables
- Set language_code
- Use narrative context
- Try accent tags
- Break into syllables
Latency Issues
- Use Flash v2.5
- Shorten text chunks
- Avoid complex tags
- Use WebSocket streaming
- Retry after delay
- Check status page
- Check plan limits and current service guidance
- Batch non-urgent jobs
Emotion Not Working
- Add contextual cues
- Use narrative descriptions
- Lower stability
- Use v3 tags
- Increase stability
- Reduce style exaggeration
- Use calmer language
- Switch to Flash or Multilingual for more controlled output
Character Limit Issues
- Flash v2.5: 40k limit
- Multilingual v2: 10k limit
- Eleven v3: 5k limit
- Split by sentences
- Send 200-500 char chunks
- Flush after sections
- Use queue for long form
- Store progress markers
ElevenLabs FAQ
Fast answers to common ElevenLabs questions people search before using the API or picking a model.
What is the best ElevenLabs model right now?
It depends on the job: use Flash v2.5 for low latency, Multilingual v2 for polished multilingual narration, and Eleven v3 for expressive dialogue or character-style output.
Is ElevenLabs only for text to speech?
No. ElevenLabs now spans text-to-speech, speech-to-text, voice cloning, voice design, streaming, agents, dubbing, and other audio workflows.
Which ElevenLabs model should I use for real-time apps?
Start with eleven_flash_v2_5 for low-latency generation, especially when building chat, assistant, or agent-style voice interfaces.
What is the difference between IVC and PVC?
Instant Voice Cloning is faster and lighter for quick tests, while Professional Voice Cloning is the higher-quality path for serious production workflows and shareable cloned voices.
Does ElevenLabs support multiple languages?
Yes. Coverage varies by model, with Eleven v3 offering the broadest TTS language support, while Multilingual v2 remains a strong choice for high-quality multilingual narration.
More Cheatsheets
Other quick-reference guides you might find useful.
The 2026 Browser Landscape
Major Browsers, Engines, Privacy & Security
Quick reference to the 2026 web browser landscape - market share, engines (Blink, WebKit, Gecko), performance, privacy, extension risks, and a decision table for picking the right browser.
LiveKit Agents
Real-Time Voice & Multimodal AI
Complete quick reference for LiveKit Agents - architecture, chained vs realtime pipelines, STT/LLM/TTS integrations, tools, workflows, turn detection, and deployment.

WebMCP
W3C Browser AI Tool API Reference
Complete quick reference for the W3C WebMCP browser API - register JavaScript functions as AI-callable tools with full IDL, code examples, and security guidance.
Puppeteer
Headless Chrome & Firefox Automation
Complete quick reference for Puppeteer v24 - Browser/Context/Page hierarchy, modern Locator API with pseudo-selectors, request interception, BiDi, and Docker production patterns.
Playwright
End-to-End Testing & Browser Automation
Complete quick reference for Playwright - Browser/Context/Page/Locator primitives, locator strategies, web-first assertions, Codegen, Trace Viewer, language bindings, and best practices.
LangChain
LLM Agents, Tools, RAG & Models
Complete quick reference for LangChain - init_chat_model universal interface, @tool decorator, create_agent with memory and structured output, and full RAG pipeline.

MCP
Model Context Protocol Reference
Complete quick reference for the Model Context Protocol - architecture, primitives (Tools, Resources, Prompts), JSON-RPC transport, security best practices, and ecosystem overview.

Agent Skills
SKILL.md Spec & Authoring Reference
Complete quick reference for Agent Skills - SKILL.md spec, progressive disclosure, directory conventions, authoring patterns, scripts, description optimization, output-quality evals, and client integration.